Right at the end of class on Friday I finished my ruby permutations implementation, but didn't get a chance to blog it.
Sam also wrote a python version and explained the yield statement to me. I even wrote about it in Thursday's post, but I still don't really understand what is happening here. I'll try to get around to looking a bit more closely at the code and figure out how it works.
Saturday, March 28, 2015
Friday, March 27, 2015
3/27/15 - Strange Javascript
Finn had posted this code snippet on his blog a couple of days ago, and Kevin wanted to talk to me about it
If you actually run this in a terminal, javascript throws an error:
Then console.log(variablesObj) ->
So now we can do
It's also good to note that if you set
Uncaught TypeError: Cannot read property 'otherVariable' of undefined. This is attempting to treat a javascript function directly as an object, which isn't allowed. If you do console.log(variables) it prints:function variables(){
this.number = 1;
this.stringVariable = "test";
this.otherVariable = 2.0;
}
and console.log(variables()); [notice the () after variables] prints:undefinedIn order for this to work as intended, you need to get an object instance from this class:
var variablesObj = new variablesThen console.log(variablesObj) ->
variables {number: 1, stringVariable: "test", otherVariable: 2}
So now we can do
variablesObj.number, variablesObj.stringVariable, etc.It's also good to note that if you set
variablesObj.number = 2, the field will update. The initial code of setting number to 1 is only run once, when the object is first instantiated with the new keyword.
Thursday, March 26, 2015
3/26/15 - Tree Isomorphism
Today, Sam and I worked on UMD contest problem 4 from 2013, Tree Isomorphism. Basically, it gives you two string representations of trees, which could have any number of child nodes, and asks you to develop an algorithm to determine whether the trees have the same "structure", disregarding the actual data of the nodes.
First, we developed a TreeNode class, and started writing an algorithm to check if the trees were the same. Originally I figured we could just do a traversal of each tree and see if the connections were the same, but Sam pointed out that this approach would only work if the trees had the exact same structure in the exact order, which isn't necessarily the case. Instead, we wrote a recursive method that would generate all the possible orderings of child ListNodes for each parent ListNode, in a tree. Then each of these permutations was checked against the other tree, because if they were isomorphic, one of the permutations of tree A would eventually be an exact match for tree B.
The method generating all the permutations was the most difficult part, and we ended up having to look up how to do this as a hint. What our finished product did was traverse the nodes from root to leaves, and removing one element at a time from the list of nodes, then generating all permutations of the remaining nodes by making a recursive function call until that had been done for all elements. The element that had been removed initially was then stuck back onto the beginning of the list.
It was tough, but Sam kindly helped me through it and did a good job of letting me think for myself. Recursion is something I have a lot of trouble picturing in my head, so hopefully I will have some more time to really understand how our permutations method works (In theory I understand it, but I'm not sure I could explain it to someone–I think my explanation in this post is probably missing some things)
Sam also re-wrote the permutations method in python, which was much easier to read. He also showed me the
It looks like
First, we developed a TreeNode class, and started writing an algorithm to check if the trees were the same. Originally I figured we could just do a traversal of each tree and see if the connections were the same, but Sam pointed out that this approach would only work if the trees had the exact same structure in the exact order, which isn't necessarily the case. Instead, we wrote a recursive method that would generate all the possible orderings of child ListNodes for each parent ListNode, in a tree. Then each of these permutations was checked against the other tree, because if they were isomorphic, one of the permutations of tree A would eventually be an exact match for tree B.
The method generating all the permutations was the most difficult part, and we ended up having to look up how to do this as a hint. What our finished product did was traverse the nodes from root to leaves, and removing one element at a time from the list of nodes, then generating all permutations of the remaining nodes by making a recursive function call until that had been done for all elements. The element that had been removed initially was then stuck back onto the beginning of the list.
It was tough, but Sam kindly helped me through it and did a good job of letting me think for myself. Recursion is something I have a lot of trouble picturing in my head, so hopefully I will have some more time to really understand how our permutations method works (In theory I understand it, but I'm not sure I could explain it to someone–I think my explanation in this post is probably missing some things)
Sam also re-wrote the permutations method in python, which was much easier to read. He also showed me the
yield keyword in python, which is something I had come across in ruby but never really understood. Basically it is used with what is called a generator, a class that is iterable and generates values on the fly. Each time the code calling the generator increments, the next yield statement is evaluated and the value is sent to the function calling the generator.It looks like
yield in ruby is a bit different. Instead of being used to generate data to be iterated over, yield statements in ruby act as a way to pass data into a block that has been passed to the function. I actually don't like this, because it's all very implicit and hard to understand (at least as someone unfamiliar with this behavior).
If you're unfamiliar, in ruby curly braces can be used to pass blocks of code into functions, so the statement foo {...} passes the code block {...} into the method foo, even though foo isn't defined to take any arguments.
Wednesday, March 25, 2015
3/25/15 Karma Setup
Apparently, I didn't actually follow all the steps I wrote about in my blog post yesterday (or it got deleted? I'm not sure) but I had to reinstall the karma-firefox adapter and the karma-mocha adapter. I also updated our unit tests slightly.
I also signed up for the codementor.io Firefox OS workshop.
I also signed up for the codementor.io Firefox OS workshop.
Tuesday, March 24, 2015
3/24/15 - Karma Setup
We worked more on setting up Karma and Mocha.
First I ran
Next, I added mocha and chai to the frameworks array in the config. Several dependencies also need to be downloaded through npm. We got karma-firefox-launcher (
We also got chai, which is a library that allows you to do
Note: I'm not sure what the
In order to make our lives easier, we also got karma-cli, which allows you to run karma directly from the command line.
With that done, you should be able to run
Finn also expanded the testing of
One problem I see with this is if anyone else wants to run tests in our repo, they have to install all these dependencies, which is annoying for them.
First I ran
karma init, which asks a series of questions about what you want Karma to do, and generates a karma.conf.js file based on your responses. I also had to add some additional stuff myself. Here's what Finn and I ended up with at the end of the period today.Next, I added mocha and chai to the frameworks array in the config. Several dependencies also need to be downloaded through npm. We got karma-firefox-launcher (
npm install karma-firefox-launcher) so that karma could start a firefox instance, and karma-mocha so that karma can talk to mocha (npm install karma-mocha).We also got chai, which is a library that allows you to do
#expect(), #should(), and other test-related methods in mocha tests with npm install chai --save-dev. We then got the karma-chai adapter (npm install karma-chai --save-dev)Note: I'm not sure what the
--save-dev flag does, but it apparently logs it as a dependency in some sort of json file (I assume this is more geared towards node projects though). There's also the -g flag, which installs globally.In order to make our lives easier, we also got karma-cli, which allows you to run karma directly from the command line.
With that done, you should be able to run
karma start to start a web server with karma, and then in a new terminal, karma run. Make sure you run from the librifox directory so that karma will be able to find the karma.conf.js file.Finn also expanded the testing of
#stripHTMLTags (since that's the most easily testable method right now!)One problem I see with this is if anyone else wants to run tests in our repo, they have to install all these dependencies, which is annoying for them.
Monday, March 23, 2015
3/23/15 - Mocha and Karma
Today Finn and I worked on setting up our test suite. We're using Mocha, which I like because it is syntactically very similar to rspec, the ruby test suite I used for NSFPatents2. We're also using Karma--since Mocha runs on node.js, things like
Here's Finn's breakdown of how we got Mocha and Karma to work.
Karma is a wrapper for Mocha that allows the tests to run in an actual browser environment, so assumptions that are made in our code like 'there is a window we can add elements to' will be valid (node.js is a server, so it doesn't have any of that). Right now we are trying to figure out how to have our app.js and eventually other files accessible so that we can test them.
Also, I'm not sure exactly how Karma handles things, but I would imagine we need to set it to test in Firefox. Fxpay, which I'm using as reference to try to set this stuff us, does this here in their Karma config file. I think we'll also need to install this plugin for Karma (This page was also helpful).
I'm excited to start testing because I think it will give us a reason to really spend a lot of time improving the structure of our code. For example, methods like this are pretty much untestable in their current state. I'm thinking that we should have separate objects that handle page generation for each of our pages. I'm not sure how object inheritance works in javascript (or if it even exists) though.
window and jQuery are undefined, and our javascript would of course throw errors because of this and cause our tests to fail.Here's Finn's breakdown of how we got Mocha and Karma to work.
Karma is a wrapper for Mocha that allows the tests to run in an actual browser environment, so assumptions that are made in our code like 'there is a window we can add elements to' will be valid (node.js is a server, so it doesn't have any of that). Right now we are trying to figure out how to have our app.js and eventually other files accessible so that we can test them.
Also, I'm not sure exactly how Karma handles things, but I would imagine we need to set it to test in Firefox. Fxpay, which I'm using as reference to try to set this stuff us, does this here in their Karma config file. I think we'll also need to install this plugin for Karma (This page was also helpful).
I'm excited to start testing because I think it will give us a reason to really spend a lot of time improving the structure of our code. For example, methods like this are pretty much untestable in their current state. I'm thinking that we should have separate objects that handle page generation for each of our pages. I'm not sure how object inheritance works in javascript (or if it even exists) though.
Friday, March 20, 2015
3/20/15 - Mocha, parseHTML
First of all, I messed up a commit to the repo. I forgot to save my changes in WebIDE before committing, so this was added, which is definitely not what we want! I committed the intended code, which makes a couple of changes (I love the branch compare feature, by the way!). First of all, I pulled out the html stripping code into a dedicated method. My two options seemed to be using either regular expressions or jQuery for the stripping. I opted to use a regex, because jQuery has some weird behavior that I would not want hidden away and waiting to cause problems for code using
Also, somehow we fixed the search function bug where it would only allow one search, even though we don't know what fixed it. While it's good that it's fixed, it's worrying that seemingly unrelated functions are intertwined.
Also, I started looking at Mocha, but we ran out of time. I had a little blast of nostalgia though, because I was looking over my tests from NSFPatents2, which I wrote over the summer.
#stripHTMLTags. For example, passing a string like 'abcdef' does something unexpected: $('abcdef').text() returns "", I guess because 'abcdef' isn't valid html and so it just...ignores everything. At first, I fixed this by ensuring the string was always enclosed in html tags: $('<html>' + string + '</html>').text() to ensure that in the case of no tags being present, the string is still returned. I realized that this approach ugly and probably brings up other issues. The regex, on the other hand, is very transparent in what it is doing, and easy to test as well (I'm using rubular for this because I can directly link to saved regex tests), so I chose to use it over jQuery.Also, somehow we fixed the search function bug where it would only allow one search, even though we don't know what fixed it. While it's good that it's fixed, it's worrying that seemingly unrelated functions are intertwined.
Also, I started looking at Mocha, but we ran out of time. I had a little blast of nostalgia though, because I was looking over my tests from NSFPatents2, which I wrote over the summer.
3/19/15 - NSF Meetup and Refactoring
At NSF yesterday, I got a chance to talk to Kevin about some design questions I had relating to the Librifox code. Since I don't have a lot of experience with stuff like storing UI state, I wanted to get his input on our current approach. After talking to him, I think it makes sense to move the
I also asked Kevin what he thought of my approach to our
I also wanted to make sure I added in this quote from a guy named Tony Hoare that Kevin sent me a while ago after my "bad code vs. good code" post.
"There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult."
bookCache directly into the UIState object, so that it is 'insulated' from the rest of the code. I think that this makes sense, because we never really use bookCache outside of the context of UIState, so the two are clearly linked. This would also allow us to have more control over what code can do to the bookCache by moving it out of global scope.I also asked Kevin what he thought of my approach to our
XMLHttpRequest code. I was worried that having a base function that is referenced by other functions which pass in specialized strings might not be a good thing to do, but he said that this was definitely a valid design pattern. The getDataFromUrl method is essentially a template, and the three specific methods pass in specialized parameters to customize the specific steps that are taken to launch the request.I also wanted to make sure I added in this quote from a guy named Tony Hoare that Kevin sent me a while ago after my "bad code vs. good code" post.
"There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult."
Wednesday, March 18, 2015
3/18/15 - Audio Refactoring
Today we worked on refactoring the audio code. It turns out that all this code in our previous versions of app.js, besides being incredibly hard to understand, was never actually called! The
Finn also caught a bug that I didn't notice yesterday. I always use the search 'abc' in our search bar, which gives just one result—a book on vegetable gardening or something. However, when Finn searched just 'a', a bunch more books were shown, and some of them were displaying with incorrect formatting. He said that the title and description fields of Librivox's book json sometimes contained HTML tags, which were being added to our code.
In order to strip these out, I converted those fields to html using jQuery's
We also added a position property to the
We also have a bug where the search function stops working after the first search, which definitely needs to be fixed. I think I know why this is happening, but I didn't get a chance to test it out. More on that tomorrow...
$('#audioSource') would always return an empty search, because this code was executing as soon as index.html loaded, and the #audioSource element only exists in book.html. We were able to delete pretty much all of this code, and moved the event handler into our book.html pagecreate handlerFinn also caught a bug that I didn't notice yesterday. I always use the search 'abc' in our search bar, which gives just one result—a book on vegetable gardening or something. However, when Finn searched just 'a', a bunch more books were shown, and some of them were displaying with incorrect formatting. He said that the title and description fields of Librivox's book json sometimes contained HTML tags, which were being added to our code.
In order to strip these out, I converted those fields to html using jQuery's
#parseHTML method, and then getting the text of the resulting object (code example). I feel like there's probably a more succinct way to do this, though. This method also seems quite innefficient. #parseHTML for some reason does not return a jQuery object, so we must $() that, then call #text() on it. If there is, in fact, no better way to do this, the code should at the very least be pulled out into its own method, since we are going to need this functionality quite a bit.We also added a position property to the
Chapter object, and have it updating each time the audio player fires a 'timeupdate' event. The current method we're using for this involves using jQuery to select the audio element, then getting the time property. This method fires incredibly fast, and having to do a jQuery element selection each time is inefficient, since I'm sure the event object already contains the current audio position.We also have a bug where the search function stops working after the first search, which definitely needs to be fixed. I think I know why this is happening, but I didn't get a chance to test it out. More on that tomorrow...
Tuesday, March 17, 2015
3/17/15 - Good Enough?
I realized as I was blogging yesterday that our
One thing I ran into was the problem of naming my methods. I've never been all that creative at coming up with names, and I feel like you have to find a balance between descriptive and succinct. For example, I wasn't sure whether to go with
Trying to have descriptive method and variable names is one of the reasons I prefer snake_case to camelCase: I try to write my method names like they're a sentence describing what the method does, which lends itself much better to snake_case, because the underscores, rather than capital letters, denote spaces. In this case, my method could be described by the statement 'set the current chapter by using the index', which would then become
I'm also not sure whether these methods should return the values they find (lines 8 and 12), since they are supposed to just be setting the value within the object. Setter methods returning values is a very Java thing to do, and Java isn't that great, so maybe we should avoid that. Actually, now that I think about it, these return values aren't actually ever made use of when calling the methods, so I'll just remove them. I'm going to leave this part in my blog, though, because it's still a good thing to think about.
Here's my commit diff, and here's what I ended up with for the
I also noticed that the
Book object was beginning to take on too much responsibility, as we added a currentChapter property to manage which chapter the user had clicked on in the interface. We definitely don't want Book to know anything about the actual UI state of the app, because that is well beyond it's scope of use. Instead, I added a UIState which takes the place of selectedBook as our global variable for passing book data into the pagecreate methods.One thing I ran into was the problem of naming my methods. I've never been all that creative at coming up with names, and I feel like you have to find a balance between descriptive and succinct. For example, I wasn't sure whether to go with
#setCurrentChapterByIndex() or #currentChapterByIndex() or something even shorter than that, which would look better, but be less descriptive about what the method is actually doing. Since the method is setting the current chapter based on the index, I opted for the former method name. I could remove these methods all together, but getting chapter and book objects by index/id seems to be a pretty common occurrence in our code, and I'd rather not duplicate code by scattering this conversion throughout our page generation methods.Trying to have descriptive method and variable names is one of the reasons I prefer snake_case to camelCase: I try to write my method names like they're a sentence describing what the method does, which lends itself much better to snake_case, because the underscores, rather than capital letters, denote spaces. In this case, my method could be described by the statement 'set the current chapter by using the index', which would then become
#set_current_chapter_by_index. I find this to be more readable than #setCurrentChapterByIndex, although that's just my opinion. Since the javascript standard is camelCase, I'll stick with that.I'm also not sure whether these methods should return the values they find (lines 8 and 12), since they are supposed to just be setting the value within the object. Setter methods returning values is a very Java thing to do, and Java isn't that great, so maybe we should avoid that. Actually, now that I think about it, these return values aren't actually ever made use of when calling the methods, so I'll just remove them. I'm going to leave this part in my blog, though, because it's still a good thing to think about.
Here's my commit diff, and here's what I ended up with for the
UIState function.I also noticed that the
<code> tag styling was sort of hard to read, so I darkened the font color and added some padding. Here's a comparison of the new code tag style and the old code tag style (notice the text doesn't go all the way to the edge of the gray rectangle anymore).
Monday, March 16, 2015
3/16/15 - Refactoring with Friends!
Today Finn and I started refactoring together. I think my code gave him a good example of how useful Javascript objects can be as a store of data, and I also explained some other stuff that had been bothering me about the code, like the idea that duplicated code should be extracted into a method rather than copied and pasted.
We ended up merging the
[Also, sidenote, I figured out how to compare snapshots of the repo at certain times, as seen in the comparison link above! I used this resource to figure out how to set the times, and although I didn't use it, this resource is cool: comparing the repo between specific commits (which don't have to be right next to each other)]
We removed a bunch of comments that were no longer necessary and just took up lines, as well as this whole section of code, which was no longer necessary because of our Book persistence between methods.
We were also trying to figure out the best way to keep track of what book a user is currently interacting with. After a user selects a book from the search, we need a way for the resulting chapter and book page generation methods to know which book was selected. Previously I had been passing an id in with the url, but we opted instead to go with a global
Here's what we ended up with. The
I think it's also worth talking about a very minor thing Finn and I came across when working on getting the app to respond correctly to a user selecting a specific chapter to listen to. We need some way to store the specific chapter that was selected, and our current approach as of the end of class was to say that we'll set this value in
Also, now that I'm looking at it, it seems like our Book object is taking on too much responsibility: it's acting as both a store of book data and as a store of UI state, which is BAD! I think we'll need some separate construct to store the UI state so we don't end up with all these super-objects that know everything about everything.
We ended up merging the
alex_refactor branch with the master branch, which went without a hitch because no changes had been made to master since I forked it on Thursday. Today, we continued refactoring where I had left off from yesterday. Here's a comparison of our code between today and yesterday (focus on app.js) [Also, sidenote, I figured out how to compare snapshots of the repo at certain times, as seen in the comparison link above! I used this resource to figure out how to set the times, and although I didn't use it, this resource is cool: comparing the repo between specific commits (which don't have to be right next to each other)]
We removed a bunch of comments that were no longer necessary and just took up lines, as well as this whole section of code, which was no longer necessary because of our Book persistence between methods.
We were also trying to figure out the best way to keep track of what book a user is currently interacting with. After a user selects a book from the search, we need a way for the resulting chapter and book page generation methods to know which book was selected. Previously I had been passing an id in with the url, but we opted instead to go with a global
selectedBook variable, at least until we come up with a better solution. I realized passing the id in with each url didn't feel right, as we would have had to include the id in every single app url for every single page, when it makes more sense in my opinion just to have a global variable.Here's what we ended up with. The
book-id attribute of the search result is set, then retrieved on click where it is evaluated to a book object from the bookCache and set as selectedBook. I don't think this is a perfect solution, but it certainly seems less clunky than passing the id in via the url and having to parse it out again in each pagecreate.I think it's also worth talking about a very minor thing Finn and I came across when working on getting the app to respond correctly to a user selecting a specific chapter to listen to. We need some way to store the specific chapter that was selected, and our current approach as of the end of class was to say that we'll set this value in
Book once the user selects a chapter from the chapter selection screen. I wanted to make it clear that the Book object would sometimes have a currentChapter property defined at some point, so I had Finn add this line to show anyone who is unfamiliar with our code that this key might exist at some point. However, I don't know if that follows Javascript's style conventions.Also, now that I'm looking at it, it seems like our Book object is taking on too much responsibility: it's acting as both a store of book data and as a store of UI state, which is BAD! I think we'll need some separate construct to store the UI state so we don't end up with all these super-objects that know everything about everything.
Sunday, March 15, 2015
Changes 3/14/15 to 3/15/15 - The Refactoring Continues
Over the weekend I've continued to refactor the code, although it's pretty slow going because the code is very hard to change.
I have to be honest here: the code that made our app work was very poorly thought out. As I mentioned earlier, using
This is what I was getting at in the TL;DR (that means 'too long; didn't read' for all you old folks out there) of my previous post: that working code and good code are not the same thing. Yes, this code worked, but it wouldn't be called good code by any stretch.
Here's something to think about in relation to web requests: let's say we get to the point where our app almost has persistent book storage between app restarts. And let's suppose a user has downloaded an audiobook to listen to on his commute to work (or whatever). However, he doesn't have access to a data connection while in transit, and suddenly finds that he can't see the book he has downloaded, except for maybe the filename of his downloaded audio file because suddenly the web requests required to generate the chapters list and book player pages aren't going through. Relying on web requests for every page that needs book data is a bad idea, because it makes our app all but unusable without an internet connection.

In order to fix this, I first created
So I changed a couple of important things between this commit and the last one. In order to make the book and chapter data more persistent (it doesn't survive app restarts, but doesn't have to be downloaded from LibriVox each time), I created a global
The reason why I've structured the code like this is because we need to have a book show up in search results, then, if clicked on, show chapters and other data in a completely separate method. The book object needs to be accessible to both methods, and it doesn't seem like there's a way to pass a variable directly from one
Another thing I noticed when refactoring, is that I ended up with a function within a function, which suggests that this method's responsibility should probably be refactored into an object of some sort.
I wasn't able to refactor all the code, but I've made a start. I actually didn't get a chance to start on the time storage stuff that I had mentioned a couple days ago in this post, so I'll probably work on that on Monday.
I have to be honest here: the code that made our app work was very poorly thought out. As I mentioned earlier, using
localStorage in the manner we were would only allow for one book at a time to be saved and read. As I was looking over the code for refactoring, I also noticed that there was no data persistence in regards to the information pulled from the Librivox server. Any time we needed any information about a book (which is quite often, as you would expect) we would send another request to the server for the book json, even if an identical request had been sent seconds before. And as I mentioned in an earlier blog post, these requests were copied and pasted almost line for line from one method to another.This is what I was getting at in the TL;DR (that means 'too long; didn't read' for all you old folks out there) of my previous post: that working code and good code are not the same thing. Yes, this code worked, but it wouldn't be called good code by any stretch.
Here's something to think about in relation to web requests: let's say we get to the point where our app almost has persistent book storage between app restarts. And let's suppose a user has downloaded an audiobook to listen to on his commute to work (or whatever). However, he doesn't have access to a data connection while in transit, and suddenly finds that he can't see the book he has downloaded, except for maybe the filename of his downloaded audio file because suddenly the web requests required to generate the chapters list and book player pages aren't going through. Relying on web requests for every page that needs book data is a bad idea, because it makes our app all but unusable without an internet connection.
In order to fix this, I first created
Book and Chapter classes, where args are passed in and a Javascript object is created. (If you need to brush up on Javascript objects, here's the w3schools explanation.) Additionally, I moved the logic for stripping the <CDATA[[]]> tag from the rss' chapter heading text into the Chapter class, which cleaned up the chapter list pagecreate method a bit.So I changed a couple of important things between this commit and the last one. In order to make the book and chapter data more persistent (it doesn't survive app restarts, but doesn't have to be downloaded from LibriVox each time), I created a global
bookCache. This object functions as a hash, with book ids as keys and Book objects as values. That way, given the id of a book, and assuming it has been added to the bookCache, the actual book object associated with that id can be retrievedThe reason why I've structured the code like this is because we need to have a book show up in search results, then, if clicked on, show chapters and other data in a completely separate method. The book object needs to be accessible to both methods, and it doesn't seem like there's a way to pass a variable directly from one
pagecreate to another, which is disappointing, because I don't find the solution I've come up with to be a very elegant one.Another thing I noticed when refactoring, is that I ended up with a function within a function, which suggests that this method's responsibility should probably be refactored into an object of some sort.
I wasn't able to refactor all the code, but I've made a start. I actually didn't get a chance to start on the time storage stuff that I had mentioned a couple days ago in this post, so I'll probably work on that on Monday.
Friday, March 13, 2015
Changes 3/13/15 - Refactoring Begins
'pagecreate' event fires as the page is loading, while the 'pageinit' event fires after the page has fully loaded (link to documentation). We'd been using the 'pagecreate' event without, but I went ahead and switched all of them over to 'pageinit's just in case, since that's what we really want.Edit: I didn't realize that the source that gave me that information was jQuery 1.2.0 documentation. The current documentation says to use
'pagecreate'It's also worth noting that I've started my own branch in the repo to make sure I don't break anything Finn might be working on.
I've started working on moving our book variables from being written to
localStorage as a bunch of keys to a dedicated Book object, but I'm having trouble deciphering and refactoring the code. First of all, the code in question is duplicated (method 1, method 2), which makes it harder to refactor. Instead of copying and pasting code in spots where you are trying to do similar or identical things, duplicated code should be pulled into a method which can be called in each place that requires it. That way, when refactoring that section of code, you only have to make changes in a single place.Another thing that makes this code very hard to read is that there are all these lines that were clearly half-finished thoughts or temporary debug things that didn't get deleted. For example, these lines here do nothing (well, I guess they log to console, but that's more of a debug thing that's not really necessary anymore). Also, as far as I can tell, the "url" key referenced in the if statement there will always have a value if a book has ever been clicked on by the user any time the app has been run (
localStorage is persistent), so the if statement does effectively nothing. This code is very confusing, and in my opinion, unnecessary, so I removed it.After I finished refactoring, I had gone from this to this. Just by removing unnecessary/unused variables and comments (and a few other minor things), the method went from 38 lines to 25 lines with the exact same functionality.
I'll talk to Finn on Monday about writing the simplest code possible to do a task, because simpler a slice of code is, the easier it is to understand and work with (there's a specific name for this, but I'm blanking on what it is). Even though they are functionally the same, turning these 7 lines of code into 2 lines of code (also shown in the gist below) is definitely an improvement, because the two lines are way more concise and understandable than the seven.
TL;DR Bad code can work perfectly, but 'working' just isn't good enough. Write good code—code that works, is well thought out, and is easy to understand!
Wednesday, March 11, 2015
Changes 3/11/15 Part 2 - Refactoring
One of the things that Sandi Metz talks about in her book Practical Object Oriented Design in Ruby (fantastic book by the way) is how to reduce the inherent cost of change in a project.
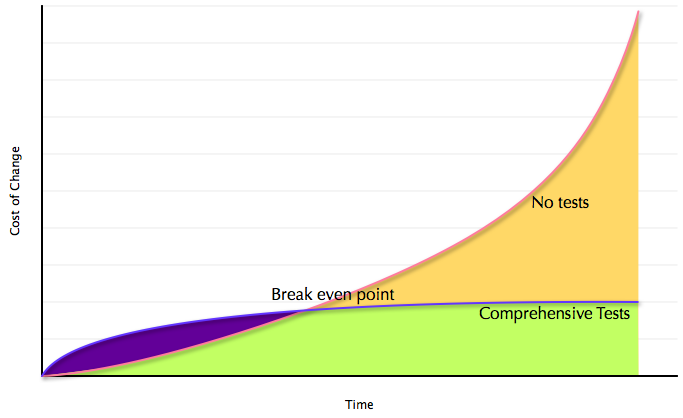 Things like well thought out objects with clear responsibilities, clean and easy to understand code, etc. will make later development much easier, even if you lose some productivity early on. (Though in relation to the graph, I don't think unit testing is necessary or feasable for this project in particular)
Things like well thought out objects with clear responsibilities, clean and easy to understand code, etc. will make later development much easier, even if you lose some productivity early on. (Though in relation to the graph, I don't think unit testing is necessary or feasable for this project in particular)
We've (well, really, Finn has for the most part) been adding a lot of features to the app, but I feel like we've moved too fast and now the cost of change is catching up with us. We've got all this code, and it's not very well organized at all--we've got about 40-50% of the essential functionality right now, but getting the next 10% and the next 10% after that and so on is just going to take longer and longer as our code grows (like the yellow line on the graph).
As it stands, I think there's way too much functionality being defined within methods which really needs to be pulled out into objects with designated responsibilities. For example, this method currently handles every bit of behavior associated with selecting a book. The UI specific stuff in the method should stay where it is, but the url parsing and playhead position (as I keep mentioning but still haven't fixed!) code needs to be refactored out.
I guess I've just sort of been swept off my feet with the pace that Finn is adding features. When I'm coding on my own, I tend to go a slower and take a lot of time to think through how to best follow the agile philosophy, so that my productivity can be closer to the purple line on the graph rather than the yellow one. (You can tell I like to take my time, because I've written three blog posts about refactoring the playhead position functionality and still haven't actually done it!)
That's not to say I don't like working on this project or group projects in general: working with others in a codebase is something that is going to be central to any programming job, and I think this is a great experience, since I've never worked directly with someone else on an application before.
We've (well, really, Finn has for the most part) been adding a lot of features to the app, but I feel like we've moved too fast and now the cost of change is catching up with us. We've got all this code, and it's not very well organized at all--we've got about 40-50% of the essential functionality right now, but getting the next 10% and the next 10% after that and so on is just going to take longer and longer as our code grows (like the yellow line on the graph).
As it stands, I think there's way too much functionality being defined within methods which really needs to be pulled out into objects with designated responsibilities. For example, this method currently handles every bit of behavior associated with selecting a book. The UI specific stuff in the method should stay where it is, but the url parsing and playhead position (as I keep mentioning but still haven't fixed!) code needs to be refactored out.
I guess I've just sort of been swept off my feet with the pace that Finn is adding features. When I'm coding on my own, I tend to go a slower and take a lot of time to think through how to best follow the agile philosophy, so that my productivity can be closer to the purple line on the graph rather than the yellow one. (You can tell I like to take my time, because I've written three blog posts about refactoring the playhead position functionality and still haven't actually done it!)
That's not to say I don't like working on this project or group projects in general: working with others in a codebase is something that is going to be central to any programming job, and I think this is a great experience, since I've never worked directly with someone else on an application before.
Changes 3/11/15 - IRC Headaches and Refactoring
Today, I spent about 20 minutes trying to find an IRC client for windows. First I tried mIRC, which is a 30 day free trial, and on top of that has a terrible interface. I uninstalled that pile of crap, and installed HexChat instead, which has a more understandable interface, but still wasn't that great. Finn had to help me, because I wasn't sure where to put the channel name (turns out you can't just do
I also added
I also started to work on the way our app saves the audio position. Currently, we have hours, minutes, and seconds saving to the HTML5 local storage, which I think is a bad idea for a couple of reasons. First of all, it's creating persistent global variables for a bunch of book related stuff each time a book is clicked on.
The player position is stored in three separate variables:
I think I'm going to continue refactoring the time storage functionality first, but it's going to be difficult because I didn't write this portion of the code and so I don't feel like I have a good understanding of what it is doing yet. Additionally, since Finn and I are working separately, I don't want to accidentally break something he is working on with my code. I'll definitely create my own branch to work from to minimize this risk, but eventually we will have to merge those branches.
irc.mozilla.org#openwebapps)
I also added
<!DOCTYPE html> to the beginning of all the app's html files, just in case that was causing issues (I don't think it was though).I also started to work on the way our app saves the audio position. Currently, we have hours, minutes, and seconds saving to the HTML5 local storage, which I think is a bad idea for a couple of reasons. First of all, it's creating persistent global variables for a bunch of book related stuff each time a book is clicked on.
The player position is stored in three separate variables:
hours, minutes, and seconds, which is unnecessarily complicated; it is storing what should really be one object, as the three values are obviously related to each other. Thirdly, this implementation only allows for the position of one book to be saved at a time, as the value is overwritten for each time a book is loaded, which I think is the most glaring issue. What if a user wants to start a second book before they have finished the first?I think I'm going to continue refactoring the time storage functionality first, but it's going to be difficult because I didn't write this portion of the code and so I don't feel like I have a good understanding of what it is doing yet. Additionally, since Finn and I are working separately, I don't want to accidentally break something he is working on with my code. I'll definitely create my own branch to work from to minimize this risk, but eventually we will have to merge those branches.
Changes 3/10/15 - Javascript Defer Problems and Videoconferencing
In LibriFox, we've been using the
Today, we removed the attribute to see what would happen. The error output for the script became much more verbose, although I think it was just finding errors that were due to the script no longer loading after the page. However, we started getting strange errors like
I think it makes sense to leave
We also videoconferenced with Marcia from Firefox, and were able to ask some of the questions we had about our project, like which IRC channels we should be asking questions in.
defer attribute like so: <script type="text/javascript" src="js/app.js" defer></script>. The defer attribute essentially tells the browser to wait until the page has been loaded before running the script (w3c link). Today, we removed the attribute to see what would happen. The error output for the script became much more verbose, although I think it was just finding errors that were due to the script no longer loading after the page. However, we started getting strange errors like
not well formed, and another about missing closing </link> tags, even though by HTML5 standards <link> tags don't require a closing tag.I think it makes sense to leave
defer on, because I don't think we've been using $(document).ready or any similar method to stop code from loading before the page.We also videoconferenced with Marcia from Firefox, and were able to ask some of the questions we had about our project, like which IRC channels we should be asking questions in.
Tuesday, March 10, 2015
Changes 3/9/15 - Blog Url Change and Blob Downloading
So the first thing I did today was change my blog url from ahirschberg-website.blogspot.com to ahirschberg-programming.blogspot.com. I didn't want all the avid readers of my blog to get confused though, so I registered a new blog under the old domain and made a post with some Javascript that redirects to this blog. The line I used was
We also started working on downloading files rather than streaming them. Our #getFileFromUrl method, which creates and sends an XMLHTTPRequest, is very reusable. I just added a shortcut(?) method (forget what these are called):
The code is really hard to navigate, especially for me since a lot of it is stuff I didn't write myself.
Additionally, our app has no structuring or objects of any sort, which makes it very hard to navigate.
This method is a good example of a problem I see in the code. The time variable is currently passed around as an
setTimeout(function() {
window.location.replace("http://ahirschberg-programming.blogspot.com")
}, 2000);
I decided to have a timer rather than instantly redirect so that visitors to the site would be able to at least glance at the message saying the blog had been moved.We also started working on downloading files rather than streaming them. Our #getFileFromUrl method, which creates and sends an XMLHTTPRequest, is very reusable. I just added a shortcut(?) method (forget what these are called):
#getBlob(url, load_callback) which just calls getDataFromUrl(url, 'blob', load_callback). This is probably a code smell or something, because I'm using a lot of magic strings and specialized methods calling a base method with specific parameters, but at the moment I don't feel like it's too pressing of an issue, especially because there are other portions of the code which will need a lot more attention.The code is really hard to navigate, especially for me since a lot of it is stuff I didn't write myself.
Additionally, our app has no structuring or objects of any sort, which makes it very hard to navigate.
This method is a good example of a problem I see in the code. The time variable is currently passed around as an
int and hours, seconds and minutes are found using math within the method. This should really be some sort of PlayTime object with the integer as an underlying variable and methods doing the math to return seconds, minutes, and hours rather than have these operations done within the method. I'm not trying to nitpick, and this is just one random thing I happened to notice when reading over the code, but also illustrates what I think is a problem with our code structure in general that we will need to deal with going forward.
Friday, March 6, 2015
Changes 3/6/15 - Small Stuff
Today was another snow day, so I didn't do much. One thing I did do was try to clean up some code we had written a couple days ago. For retrieving book information from Librivox servers, we are using JSON because it's very easy to work with in Javascript and Librivox supports it. I wrote a
 I got around to refactoring it today, and the result is definitely better, but it's not perfect. For one, it uses the magic strings
I got around to refactoring it today, and the result is definitely better, but it's not perfect. For one, it uses the magic strings
The code is getting pretty messy, and our app has a lot of functionality already (Finn has been adding tons of features!), but the app also a lot of bugs that might take a while to figure out. We have a few problems stemming from jQuery Mobile's page refresh behavior that will probably require a much better understanding of the library than what we have currently, so even "simple" fixes will probably end up taking a lot of effort.
Also, thanks to Sam's blog, I'm now using the
#getJSON(url, callback) function to do this. However, in order to parse Librivox's mp3 urls for streaming the audiobooks directly instead of downloading them, we are accessing an RSS feed, which is in the xml format. We then ended up with this method, (a direct duplication of the getJSON method with two lines difference) which is not good at all!'json' and 'xml' to account for the slight differences in the methods. Additionally, the 'xml' string isn't even referenced anywhere in #getDataFromUrl because the XMLHTTPRequest class assumes xml by default, which would be pretty misleading to someone who isn't familiar with our code. However, I don't want to focus all my attention on making this relatively insignificant thing perfect, because we have bigger fish to fry. The code is getting pretty messy, and our app has a lot of functionality already (Finn has been adding tons of features!), but the app also a lot of bugs that might take a while to figure out. We have a few problems stemming from jQuery Mobile's page refresh behavior that will probably require a much better understanding of the library than what we have currently, so even "simple" fixes will probably end up taking a lot of effort.
Also, thanks to Sam's blog, I'm now using the
<code> tag instead of my <span style='code'>, which is way less typing for me considering how often I reference code concepts!
Thursday, March 5, 2015
Changes 3/5/15 - Blogger CSS and Code Highlighting
So today is a snow day, but I was messing around with blogger and figured out how to set custom, blog-wide CSS classes. So now, if I have some code I'm referencing, and I don't want to pull it out into a Github gist, I can use my fancy new <span class='code'> tags instead of having the old <span style='font-style: monospace;'> that I've been using. Not only is span.code less typing for me, but I also made it much fancier.
I was able to do this in the Blogger menu. I went to Template > Customize > Advanced > Add CSS.
Actually, I probably should have just gone there first, but I checked out Sam's blog, and he's using <code> tags, which would be even less typing than <span style='code'>! I didn't even know that tag existed, and it looks like it's default style is to set the font-family to monospace. So I've been typing out <span style='font-family: monospace;'> all this time for no reason.
span.code {
font-family: monospace;
color: rgb(234, 85, 31);
border-radius: 1px;
background-color: rgb(239, 239, 239);
}
I also made a CSS <pre> class (as you can see above!), but I probably won't be using it as much because most of my longer code blocks will be put into gists.
Thanks, Github! Even though your css syntax highlighting is kind of ugly.I was able to do this in the Blogger menu. I went to Template > Customize > Advanced > Add CSS.
Actually, I probably should have just gone there first, but I checked out Sam's blog, and he's using <code> tags, which would be even less typing than <span style='code'>! I didn't even know that tag existed, and it looks like it's default style is to set the font-family to monospace. So I've been typing out <span style='font-family: monospace;'> all this time for no reason.
Wednesday, March 4, 2015
Changes 3/4/15 - Loading Audio Urls from RSS
Today Finn and I worked on parsing urls linking to streamable LibriVox audio. We found that each book has an rss page (formatted in xml) which contains links to mp3 files for the books. We had no problem grabbing the data from the server, as this task was very similar to getting the json data on each book. jQuery also has built in support for xml parsing, but we ran into problems iterating over all the different tags returned. The mp3 files are broken up into chapters, so we would want to iterate over each element and get the link to the mp3 and other data.
Here's an example of an rss page. Firefox actually styles it, while the other browsers just display text. Click 'view source' on the page to see the actual xml. It's weird that they have so many redundant links, as each file is linked to three times: in the url attribute of the <enclosure>, <link> and <media:content> tags. I'm assuming this is to make it compatible with the format rss readers are expecting.
I figured that a good starting place for this problem would be trying to extract the mp3 url from each <enclosure> tag. This is where we started running into problems. Given an xml file looking like this: I thought I would be able to iterate over each enclosure tag like this: What it took me an embarrassingly long time to figure out (and we're talking about an hour here) is that the variable being passed into the anonymous function inside the #each() is actually the index of the element in the selection, and not the element itself. Hence, printing i for this search would give an output of:
which gives an output of:
Another interesting thing I found today: Directly getting an element by index from a jQuery selection returns the element object directly, which doesn't include methods like #attr(). Instead, you have to pass this object back into the $() function to convert it back to a selection so that you can get access to all those methods.
I guess you can never have too much jQuery!
Here's an example of an rss page. Firefox actually styles it, while the other browsers just display text. Click 'view source' on the page to see the actual xml. It's weird that they have so many redundant links, as each file is linked to three times: in the url attribute of the <enclosure>, <link> and <media:content> tags. I'm assuming this is to make it compatible with the format rss readers are expecting.
I figured that a good starting place for this problem would be trying to extract the mp3 url from each <enclosure> tag. This is where we started running into problems. Given an xml file looking like this: I thought I would be able to iterate over each enclosure tag like this: What it took me an embarrassingly long time to figure out (and we're talking about an hour here) is that the variable being passed into the anonymous function inside the #each() is actually the index of the element in the selection, and not the element itself. Hence, printing i for this search would give an output of:
0 1I was completely unprepared for that! I assumed that the i variable was more than just an integer, and the index was just being returned by #toString() method when logging to console. It turns out that what I really wanted was:
which gives an output of:
a bthe "urls" I set in my xml.
Another interesting thing I found today: Directly getting an element by index from a jQuery selection returns the element object directly, which doesn't include methods like #attr(). Instead, you have to pass this object back into the $() function to convert it back to a selection so that you can get access to all those methods.
I guess you can never have too much jQuery!
Tuesday, March 3, 2015
Changes 3/3/15 - LibriFox Clickable search results
Over the weekend Finn and I actually worked on our project! We solved a bug where our list results wouldn't show up on the html page, even though our json was loading correctly. We thought it was a problem with the listview not refreshing (jquery mobile adds styles to list items, so you have to call $('ul').listview('refresh') after you've appended new items), but it turned out that the problem had nothing to do with jquery mobile. What was happening was upon searching for an item, you are submitting a form, and the default html action for a form submit is to reload the page. Therefore, we were appending all these list items, only to have the page refresh and clear them. We just had to add one line to app.js and our problem went away. This works because the return value for the event listener determines whether the action succeeds or not, so by returning false we are effectively cancelling the form submit and therefor the refresh.
Today, Finn and I worked on the behavior of the list items when you click them. We first had to research how jQuery mobile handles page change events, since it only changes the content of the html page, not the page itself like a "normal" website. Each list item is generated with jQuery, and a custom attribute called book-id is added. Then, when the button is clicked, this book id is saved into local storage for later use. Then, Finn worked on an event that would fire when the books.html page was loaded, which could grab the book id that my onClick event had gotten.
I also tried to make a cool navbar for my blog that would link to my website and github, but apparently you can't even set the background color of links in blogger's header field, which is dumb. Here's what I was going to add, because I think it looks good:
WebsiteGithub
Today, Finn and I worked on the behavior of the list items when you click them. We first had to research how jQuery mobile handles page change events, since it only changes the content of the html page, not the page itself like a "normal" website. Each list item is generated with jQuery, and a custom attribute called book-id is added. Then, when the button is clicked, this book id is saved into local storage for later use. Then, Finn worked on an event that would fire when the books.html page was loaded, which could grab the book id that my onClick event had gotten.
I also tried to make a cool navbar for my blog that would link to my website and github, but apparently you can't even set the background color of links in blogger's header field, which is dumb. Here's what I was going to add, because I think it looks good:
WebsiteGithub
Subscribe to:
Posts (Atom)